Ходил в советское время такой анекдот. Приезжают к нам в гости по обмену опытом японцы. Их, конечно, начинают водить по всяким разным передовым заводам, показывать новинки советского научно-технического производства. Те молча ходят, смотрят, шушукаются между собой о чем-то. Настал день отъезда. Наш представитель спрашивает у японцев: "Ваши впечатления? Ну как вам наша передовая советская промышленность?" Японцы в ответ: "Мы думали, что вы отстали от нас лет на десять, может, на двадцать. А вы, оказывается, отстали от нас навсегда".
Сейчас по поводу развала СССР много всякого говорят: тут и теория заговора, и продажность "верхушки", и естественные процессы. Однако все эти теории не объясняют главного - пресловутого вопроса "воли к власти". Наверное, один из немногих в истории случай, когда глава мировой империи добровольно отказался от власти и пошел рекламировать пиццу. У меня тоже есть на этот счет своя теория. Думаю, он банально испугался. Испугался, когда ему в США показали процессор Intel 80386 и пояснили, что американская промышленность способна, по крайней мере, десять лет подряд обеспечивать выполнение пресловутого закона Мура. А что тогда было у СССР?
Персональные компьютеры "Электроника-85", "Искра-1130", ЕС-1840 и ЕС-1841, плюс несерьезные "Корветы", "Агаты", БК-0010 и "Микроша". "Электроника-85" была своеобразной машиной, и специалисты из Dec даже нашли в ее архитектуре что-то оригинальное, но в целом это был клон выпущенной в марте 1983 года машины Dec Professional 350 с 16-битным процессором LSI-11/23. "Искра" и ЕС-1840 / 1841 базировались на советском процессоре К1810ВМ86 - аналоге Intel 8086, который был разработан в 1976 году.
А что такое процессор Intel 80386? Это была настоящая революция в области IT. Как-нибудь мы еще поговорим о нем подробнее. Пока же, в рамках данной статьи, нас интересует то влияние, которое архитектура i386 и последующих процессоров оказала на развитие производства модулей памяти.
Кэш-память
Время доступа первых микросхем DRAM было не меньше 60 нс, что соответствовало частоте 16,6 МГц. Такая же частота была у внешней шины данных самого продвинутого до 1985 года процессора Intel 80286 (выпускались модификации этого процессора на частотах 6, 8, 10, 12, 16 и - самые последние варианты - 20 МГц). Для разработчиков это были золотые денечки, не надо было ломать себе голову над вопросом о том, как обеспечить обмен данными между памятью и процессором без длительного простоя последнего. Первый вариант процессора i386 также работал на частоте 16 МГц, но частота более поздних моделей достигала 33 МГц. Чтобы не задерживать процессор с частотой 33 МГц, микросхемы памяти должны были обеспечить время доступа 30 нс, но таких микросхем еще не было.
Таким образом, компьютеры, оснащенные процессором 386DX (или его облегченным собратом 386SX) с частотами больше, чем 16 МГц, при операциях обмена данными с памятью вынуждены были часто простаивать. Это, конечно же, никого не устраивало. Появившаяся в 1989 году микросхема 486DX имела конструктивное решение, призванное как-то выровнять ситуацию с доступом к памяти. А это уже было нужно позарез, ибо если имелись и медленные микросхемы 486 с частотой всего 16 МГц, то самые шустрые 486-е имели частоту 120 МГц, что по тем временам было ох как быстро. Найденное конструктивное решение называлось кэш-памятью. Сегодня часто в русскоязычной литературе слово кэш переводят как "наличные" - от английского cash.
На самом деле имеется в виду слово cache, что в переводе с французского означает "тайник, укромное место". Кэш-память большинства компьютеров разделяется на два уровня. Кэш-память первого уровня (Level 1 - L1) представляла собой память типа SRAM, интегрированную в микросхему процессора. Работал кэш L1 на частоте процессора. Кэш второго уровня первоначально располагался на системной плате и, естественно, мог работать только на частоте системной платы. Причем наличие кэша L2 считалось необязательным, и его нужно было докупать отдельно.
Сегодня все понимают, что кэш-память - это хорошо, и чем больше ее объем, тем лучше.
Однако многие пользователи все равно не понимают, каким именно образом кэш-память убыстряет операции обмена данными между оперативной памятью и процессором. В самом деле, если кэш L1 работает на частоте процессора, то ведь данные в него все равно попадают из "медленной" оперативной памяти. За счет чего же обеспечивается убыстрение? Для того чтобы это понять, нужно иметь хотя бы самое общее представление о том, как устроена компьютерная программа. Поскольку, возможно, не все читатели Upgrade разбираются в архитектуре программ, уделю этому вопросу немного внимания.
Любая компьютерная программа, включая вирусы, обрабатывает какую-то информацию, в терминах программирования называемую данными. Программисты могут как угодно изощряться, придумывая названия переменным (контейнерам данных в программах), однако на уровне железа данные представляют собой последовательности ячеек оперативной памяти, причем эта последовательность (массив) может быть довольно-таки большой, занимая непрерывные десятки килобайт в ОП. С другой стороны, команды процессора, реализующие те или иные алгоритмы обработки информации, которые собственно и составляют программу, также хранятся в том же самом объеме памяти. Нет, конечно, операционная система распихивает их по разным сегментам, разобраться в хитросплетении которых не слишком просто. Однако с точки зрения процессора имеется единый массив ячеек памяти, каждая из которых описывается как [сегмент:смещение], причем и команды, и данные выбираются совершенно одинаково.
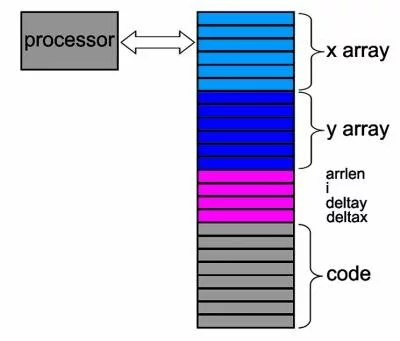
Рис. 1. Принципиальная схема взаимодействия процессоров старого типа с памятью.
На рис. 1 представлена принципиальная схема взаимодействия процессоров старого типа с памятью при выполнении следующего оператора языка "Си": for(i=0;i
Сначала из сегмента кода (он обозначен серым цветом) в командный регистр процессора загружалась первая команда цикла - проверки значения переменной i. Если это значение было меньше, чем значение переменной arrlen (ее значение могло быть загружено в один из регистров общего назначения в самом начале цикла), то загружалась следующая команда - команда загрузки в один из регистров общего назначения значения ячейки массива x. Затем эта команда выполнялась, и в регистр процессора из ячейки памяти с вычисленным адресом загружалось какое-то значение. Далее в результате выполнения еще нескольких команд в другой регистр загружалось значение переменной deltax. Значения обоих регистров складывались, и результат отправлялся в указанную ячейку памяти.
После этого еще пяток команд приводил к изменению содержимого ячейки памяти для одного из элементов массива y. В финале увеличивалось содержимое индексной переменной i, и весь цикл повторялся с самого начала до тех пор, пока не перебирались все элементы массивов x и y. И каждый раз процессор обращался к памяти - то для того, чтобы выбрать очередную команду, то для того, чтобы загрузить в какой-то свой регистр значения из ячейки памяти. В случае, когда использовалась медленная память, выполнение такого цикла было прямо-таки разорительным с точки зрения расхода процессорного времени, ибо большую часть времени процессор находился в ожидании окончания операции чтения из памяти команд или данных (либо записи обновленных данных).
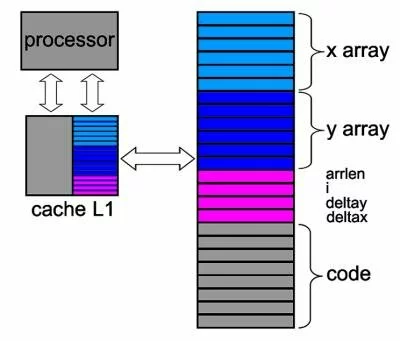
Рис. 2. Технология с использованием промежуточного буфера (кэша).
На рис. 2 продемонстрирована технология с использованием промежуточного буфера (кэша), все операции чтения-записи с которым осуществляются на частоте ядра процессора. При таком подходе из ОП выбирается фрагмент кода, из которого состоит цикл, а также блок данных, которые в этом цикле обрабатываются (на рисунке одноименные данные и код в ОП и в кэше показаны одинаковым цветом).
Преимущество такого подхода очевидно. Несмотря на то, что работа процессора остается неизменной (то есть чередующаяся выборка команд и данных), теперь он читает не из медленной ОП, а из быстрого кэша и время на ожидание поступления данных не тратит. Единственный момент, когда все-таки приходится обращаться к памяти, - изменение содержимого элементов массивов x или y. Однако в этом случае передачу измененных данных из кэша в память осуществляет уже не сам процессор (он в это время занят выполнением команды), а контроллер кэша.
Кэш-память первого уровня (рис. 2) всегда делится на две части - кэш команд и кэш данных. Наличие отдельного кэша для команд оправдано со следующей точки зрения. Реальный объем обрабатываемого в цикле массива данных может быть гораздо больше, чем место в кэше. В этом случае после обработки порции данных придется загружать в кэш новую порцию, а вот сравнительно небольшое количество команд цикла в кэше L1 в этом случае не требует дополнительной "дозагрузки".
Не следует думать, что такое эффективное использование кэша возможно всегда. Во-первых, далеко не всегда обработке подвергаются именно массивы - порой переменные, которые используются в одном фрагменте программы, расположены в различных несмежных сегментах и кэш обновляется практически для каждой переменной, что сильно снижает эффективность технологии. Однако хороший стиль современного программирования предполагает финальную оптимизацию программ, в том числе и с учетом эффективного использования кэша.
Как видно из рис. 2, в тот момент, кода кэш L1 полностью обновляется, чтение происходит из памяти, то есть в этот момент процессор все же вынужден перейти в состояние ожидания. Однако для уменьшения этого ожидания между ОП и кэшем L1 можно разместить еще один кэш (второго уровня - L2). Технология тут точно такая же. Скорость работы операций выборки из кэша L2 в старых процессорах была ниже, чем для кэша L1, но, во всяком случае, быстрее, чем у микросхем памяти. Кэш L2, как было сказано, размещался на системной плате. Однако, поскольку разработчикам постоянно хотелось его убыстрить (вернее ускорить операции обмена данными между кэшем L1 и L2), в процессоре Pentium II он переместился на плату процессора (сама плата паковалась в специальный кожух, отчего корпус процессора имел несколько странный прямоугольный вид и монтировался на системной плате как какая-нибудь звуковая карта).
Уже начиная с процессора Pentium III и Athlon, кэш L2 стал частью микросхемы процессора и мог работать как на половинной, так и на полной частоте процессора.
Ситуация, когда процессор не находит нужные данные в кэше, называется промахом кэша. Если промах произошел в кэше L1, происходит обращение в кэш L2, соответственно, если промахнулся и второй, то приходится обращаться к оперативной памяти. Для процессоров Intel Itanium предусмотрена еще и кэш-память третьего уровня. Поскольку современные процессоры и оптимизирующие алгоритмы обеспечивают уровень промахов кэша не более 10%, то при операциях чтения обращение к оперативной памяти происходит довольно редко (не более чем в 1% случаев для двух кэшей и, соответственно, в 0,1% для трех кэшей). Поэтому, кстати, разгон оперативной памяти не очень ощутим. Разумеется, промахи кэша существуют только при операциях чтения. Любая команда изменения данных тут же приводит не только к изменению содержимого кэшей, но и соответствующей ячейки ОП.
Борьба за наносекунды
Строго говоря, между самым быстрым процессором и самой медленной памятью можно выстроить такое большое количество кэшей, что процессор почти не будет простаивать при операциях обмена данными с памятью. Однако кэш-память, которая строится на микросхемах SRAM, весьма дорогая, а потому такой подход в конечном итоге привел бы к тому, что можно было вообще всю ОП строить на SRAM. Производители памяти здраво рассудили, что кэши кэшами, а неплохо бы малость пофантазировать и выдать на суд общественности какие-нибудь более быстрые модели микросхем DRAM. Для увеличения скорости доступа были разработаны новые методики доступа к памяти уже для машины на основе процессора Intel 80486.
Как мы знаем, данные в реальных модулях памяти хранятся в виде зарядов на конденсаторах, расположение которых составляет квадратную матрицу.

Рис. 3. Данные в модулях памяти хранятся в виде зарядов на конденсаторах, расположение которых составляет квадратную матрицу.
На рис. 3 представлено возможное расположение массивов y и x, схематично показанных на рис. 1 и 2 (цвета соответствующих массивов совпадают). Напомню, как происходит выборка элементов из модулей памяти. Сначала происходит накопление заряда для строба адреса строки (RAS# Precharge); затем подается сигнал RAS, указывающий, из какой строки матрицы будет производиться выборка; после этого мультиплексор переключается для подачи строба адреса столбца (RAS# to CAS# Delay), и сигнал CAS, указывающий нужный столбец, подается. После этого считывается бит, который лежит на пересечении строки и столбца, указанного сигналами RAS и CAS.
На рис. 3 видно, что при выборке всех элементов массивов y и x меняться будет только номер столбца, а номер строки останется неизменным (4-я строка). Следовательно, устанавливая каждый раз один и тот же номер строки, микросхема будет бессмысленно терять время на всех последующих операциях чтения, кроме первой. В процессоре 486 был внедрен так называемый пакетный (burst) метод доступа - доступ к четырем ячейкам памяти за один раз. При этом тайминги описывались схемой f-n-n-n, где f - количество циклов на выполнение первой операции чтения, а n-n-n - количество циклов на выполнение последующих операций.
Если схема доступа старой DRAM выглядела, как 5-5-5-5, то для памяти с пакетным доступом схема выглядела 5-3-3-3 , то есть происходило сокращение времени доступа на шесть циклов по сравнению с классической DRAM. Еще новшество - страничная разбивка - также было призвано сократить время ожидания. При страничной организации память разбивается на так называемые страницы - блоки длиной от 512 байт до нескольких килобайт. Электронная схема доступа позволяет уменьшать количество циклов ожидания при обращении к ячейкам памяти в пределах одной страницы.
Память DRAM, поддерживающая разбивку на страницы и пакетный режим, получила название "память с быстрым постраничным режимом" (Fast Page Memory - FPM). Для еще большего ускорения FPM использовался метод, названный чередованием. При этом методе на системной плате размещались парные банки данных, в одном банке размещались четные байты массива данных, в другом - нечетные. А системная логика работала таким образом, что процессор "не знал" о парных банках. В момент, когда происходила выборка байта из первого банка, во втором происходили операции установки строки и столбца. Таким образом, к моменту окончания передачи данных из первого банка, второй был уже готов к новой передаче такое перекрытие по времени обеспечивало более быструю выборку данных из памяти. Единственное неудобство этого метода было связано с тем, что на системной плате модули памяти всегда необходимо было размещать идентичными парами, то есть нельзя было разместить модули на 8 и 16 Мбайт, а только два по 8 Мбайт или два по 16 Мбайт.
Начиная с 1995 года в компьютерах на базе процессора Pentium стал использоваться новый тип памяти DRAM, получивший название EDO (Extended Data Out). Память этого типа разработала и запатентовала компания Micron Technology. EDO реализовывала схему доступа, похожую на схему чередования FPM, с тем отличием, что теперь эта схема реализовывалась в рамках одного банка, что давало пользователям возможность большего маневра при установке модулей памяти на системную плату своего компьютера. Контроллер EDO обеспечивал перекрытие двух операций доступа: установка строки и столбца начиналась еще до того, как оканчивалась передача данных предыдущей выборки. Разумеется, обеспечивать возможность работы с EDO должна была логика системной платы. Первый набор микросхем, который поддерживал EDO, был выпущен компанией Intel в 1995 году и назывался 430FX (Triton).
Память EDO пользовалась большой популярностью, но в течение 1998 года была вытеснена более быстрой памятью - синхронной DRAM, или попросту SDRAM (Synchronous DRAM). Память SDRAM завершала операции чтения всего за восемь циклов, что явно быстрее, чем 11 циклов EDO (5-2-2-2) или 14 циклов FPM (5-3-3-3). Многие циклы ожидания старой DRAM были обусловлены тем прискорбным обстоятельством, что она не была синхронизирована с тактовым генератором системной платы. Высокоскоростной синхронизирующий интерфейс памяти SDRAM поставил крест на памяти старого типа и обеспечил работу новых модулей SDRAM на частотах 100 и 133 МГц, что как нельзя лучше соответствовало новым процессорам Pentium II (вернее, скоростям их шины данных).
Но, как говорится, нет предела совершенству. В 1995 году игровая приставка Nintendo 64 была оснащена высокоскоростными чипами памяти RDRAM. Технология RDRAM была предложена калифорнийской компанией Rambus (откуда и название - Rambus DRAM). Всего компания спроектировала несколько разновидностей RDRAM, назвав их Base, Concurrent и Direct. Наибольшим успехом пользовалась Direct RDRAM (нередко можно встретить наименование DRDRAM). В октябре 2000 года компания Sony оснастила памятью DRDRAM свою игровую консоль PlayStation 2.
Однако RDRAM, наверное, не стала бы такой популярной, если бы не Intel. Еще в конце 1996 года разработчики из Intel сочли технологию RDRAM наиболее перспективной и лицензировали ее у Rambus. Этого им показалось мало. Видимо, перед их глазами стоял исторический пример договора между IBM и Microsoft, когда IBM, согласившись использовать MS-DOS, фактически сделала Билла Гейтса мультимиллиардером, не получив взамен ни единой акции. Представители Intel поступили умнее, как им тогда казалось: они заключили с Rambus соглашение, по которому Intel должна была приобрести миллион акций Rambus по низкой цене, как только более 20% чипсетов в год, выпускаемых корпорацией, будут совместимы с RDRAM. Со своей стороны Intel дала обязательство не поддерживать до 2003 года другие типы высокоскоростной памяти.
Заключив столь перспективное, на первый взгляд, соглашение, разработчики Intel приступили к созданию специального набора микросхем системной логики i820. Поскольку обсуждение чипсетов не входит в задачи данной статьи, скажу лишь, что у Intel все пошло наперекосяк, и ее руководство в 2001 году признало, что договор с Rambus был крупной ошибкой, поэтому они будут поддерживать все типы памяти, которые хорошо продаются. Поскольку компания AMD к тому времени вовсю работала с DDR-памятью, Intel приступила к изготовлению чипсетов для Pentium 4, поддерживающих DDR. Как мы хорошо знаем, это у нее получилось гораздо лучше. Неудача с чипсетом i820 косвенно повлияла и на репутацию Rambus, появилась масса статей, в которых авторы доказывали, что RDRAM - мертворожденное дитя и никакого проку от нее не будет, однако это были слишком уж поверхностные выводы.
Что же представляет собой RDRAM, почему она так заинтриговала не склонных к сантиментам представителей компании Intel? Память RDRAM не является дальнейшим усовершенствованием SDRAM, как DDR SDRAM (о которой мы поговорим чуть ниже). Свою динамическую память Rambus создала с нуля. Интерфейс RDRAM отличается от интерфейса классической SDRAM так же, как дисковый интерфейс SATA от ATA. Обычная DRAM может быть названа устройством с широким каналом, поскольку ширина канала памяти равна ширине шины данных процессора (FSB). В микросхемах RDRAM для передачи данных используется "узкая" шина - всего 16 бит, зато увеличена частота передачи до 800 МГц. Имеются также двух- и четырехканальные микросхемы. Микросхемы RDRAM устанавливаются в специальные модули RIMM (Rambus Inline Memory Modules), для увеличения производительности передача управляющей информации отделена от передачи данных.
В памяти типа RDRAM была использована двойная передача, то есть две передачи за один такт. В разной литературе дается различное объяснение этого феномена. Где-то говорится о передаче по восходящему и нисходящему фронтам сигнала, где-то пишут про левый и правый фронты, в одной статье мне попалось даже рассуждение об инверсном тактовом сигнале внутри микросхемы памяти. Отдавая должное этим внушительным определениям, я лично позволю себе воспользоваться понятием о четном и нечетном цикле.
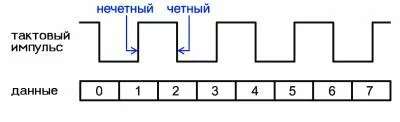
Рис. 4. Начало передачи пакета происходит в четном цикле, а каждые два бита передаются на четном и нечетном цикле.
На рис. 4 проиллюстрировано, что это такое. Вообще-то тактовые импульсы, равно как и все остальные, должны изображаться синусоидой, но в специальной литературе и технической документации используется изображение в виде верхней части крепостной стены. Из рисунка видно (во всяком случае, я на это надеюсь), что начало передачи пакета (в данном случае - восьмибитного) происходит в четном цикле, а каждые два бита передаются на четном и нечетном цикле. Чтобы разобраться в этом явлении, не следует забывать, что данные передаются не с помощью тактовых импульсов (если честно, когда-то я именно так и думал), тактовые импульсы используются лишь для синхронизации работы различных устройств. Так что принципиальной разницы нет - передавать один, два или четыре бита за один такт, лишь бы процессор понял, что это два или четыре сигнала, а не один. Фразой "нет принципиальной разницы" я, конечно, не хочу сказать, что нет никаких технических сложностей при организации такой передачи.
Всевозможные сложности, с которыми столкнулись разработчики из Intel при создании чипсета i820 (и улучшенных вариантов i840, i850), были связаны с тем, что память RDRAM работала быстрее FSB процессоров тех лет. В конечном итоге, Intel, как и весь остальной мир, пересела на DDR SDRAM. А ведь некоторые аналитики не стеснялись в конце 90-х давать вот такие прогнозы: "В свете того, что Intel собирается продвигать другую архитектуру памяти - DRDRAM, будущее DDR SDRAM представляется туманным". Да, нелегок и неблагодарен труд аналитика.
Память DDR SDRAM (Double Data Rate SDRAM) называется памятью с двойной передачей данных. Строго говоря, двойная передача DDR SDRAM точно такая же, как у RDRAM. Видимо, поэтому Rambus хочет заставить всех отчислять лицензионные за использование DDR. Однако в отличие от RDRAM, микросхемы DDR SDRAM являются "широкополосной" памятью, поскольку имеют ту же ширину, что и FSB процессора, - 64 бита. Официально стандартизация DDR была предпринята консорциумом DDR, в который вошли такие компании, как Samsung, Fujitsu, Hitachi, Hyundai, Toshiba и другие. Компания AMD, кстати, в отличие от Intel, сразу же уцепилась за эту недорогую, но быструю память. В таблице приведены отличия памяти DDR SDRAM от просто SDRAM (ее иногда называют SDR SDRAM, то есть Single Data Rate SDRAM).
|
Таблица. Сравнение памяти SDR, DDR и DDRII |
||||
|
SDR SDRAM |
DDR SDRAM |
DDRII SDRAM |
||
|
|
66-133 |
100-200 |
200-400 |
|
|
66-133 |
200-400 |
400-800 |
|
|
3,3 |
2,5 |
1,8 |
|
|
1 |
2 |
4 |
|
|
1, 2, 4, 8, полная |
2, 4, 8 |
4, 8 |
|
Самый свежий на рынке тип памяти по аналогии с SDR SDRAM и DDR SDRAM нужно было бы назвать QDR SDRAM (от Quadro), поскольку она обеспечивает передачи сразу четырех сигналов за один такт. Однако она получила более прозаическое название - DDRII SDRAM. Из таблицы можно выяснить, чем DDRII отличается от старой DDR (точность приведенных в таблице данных можно перепроверить по ссылке www.elpida.com/en/products/faq.html). В целом можно сказать, что если предел скорости передачи данных для DDR составляет 3200 Мбайт/с, то для DDRII этот показатель увеличен вдвое - 6400 Мбайт/с (продвинутые маркетологи предпочитают использовать неверную цифру 6,4 Гбайт/с). Строго говоря, для широкого распространения DDRII пока еще нет предпосылок, поскольку далеко не каждый процессор работает со скоростью, требующей что-то более быстрое, чем DDR400. Что же касается конкретных преимуществ DDRII по сравнению с DDR, то про это можно будет говорить что-то более или менее осмысленное лишь после тщательных тестов. Однако это тема уже совсем другой статьи.
Rambus - Microsoft в мире микросхем
Компания Rambus, стоящая сегодня 1,8 миллиарда долларов, была создана в марте 1990 года. Руководство компании сочло, что заниматься выпуском микросхем - дело хлопотное, а потому компания занялась разработкой высокоскоростных шин и интерфейсов динамической памяти. Свою финансовую политику Rambus строит на продаже лицензий сторонним производителям.
В мире производителей микросхем Rambus стяжала себе устойчивую славу сутяги почище Microsoft. Компания очень ревниво следит за лицензионными отчислениями от производителей систем, совместимых с RDRAM. Но этого руководству компании мало, и оно постоянно пытается доказать также и свои права на SDRAM и DDR DRAM. И некоторые производители дают слабину. Например, в июле 2004 года японская компания Matsushita лицензировала у Rambus технологию DDR.
Последняя разработка компании, которую также лицензировала Matsushita, - XDR DRAM - имеет прямо-таки впечатляющие по сравнению даже с DDRII показатели. За счет передачи восьми бит за такт (Octal Data Rate Transfers) достигается максимальная скорость передачи в 12,8 Гбайт/с! Но эта технология, как и вообще любая другая, пока встречает сопротивление на рынке PC, несмотря на то что компания Rambus сильно старается всех убедить, что именно за ее XDR DRAM будущее развития памяти для PC. И может быть, она права. Впрочем, такие заявления мы от Rambus уже слышали.